
事情是酱黄瓜的,
今天在火山引擎Force大会上,Seed-2.1-pro新鲜出炉,
有排face拿到内测的我马上让本地Agent总结几个我最近用最频繁的工作流来做测试,
说实话,看前端开发案例真的已经看腻了。要么就是来个3D游戏,或者搞个我的世界,都太常规了,我都怀疑这些模型已经把这些代码训练到自己的权重里面了。
所以我们这次直接从正式工作流上手,看看Seed-2.1-pro是怎么把一个想法,从需求一直推到一个能打开,能跑,能继续改的东西。老样子,先光速看看纸面实力的提升。
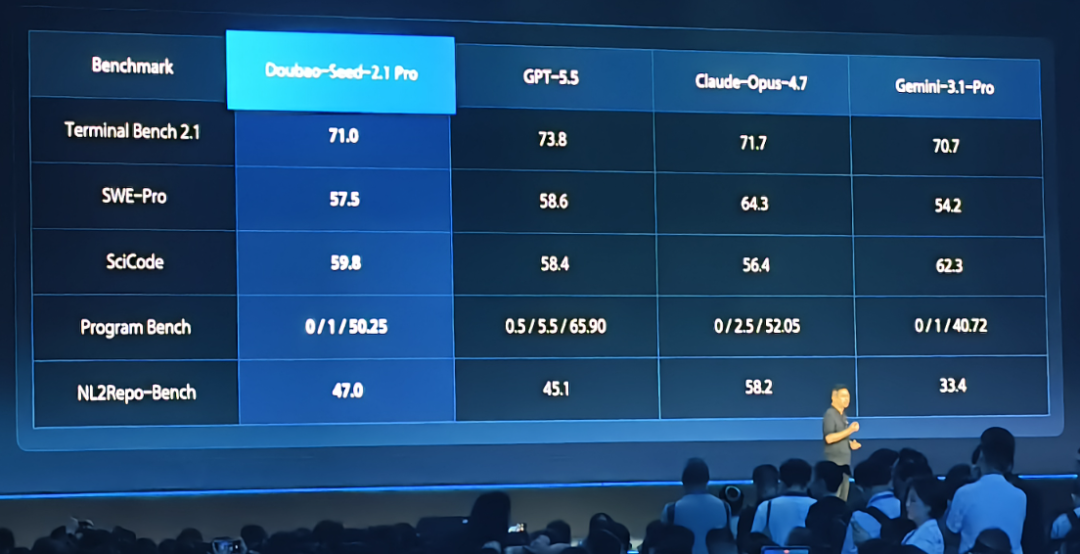
我来解读一下,
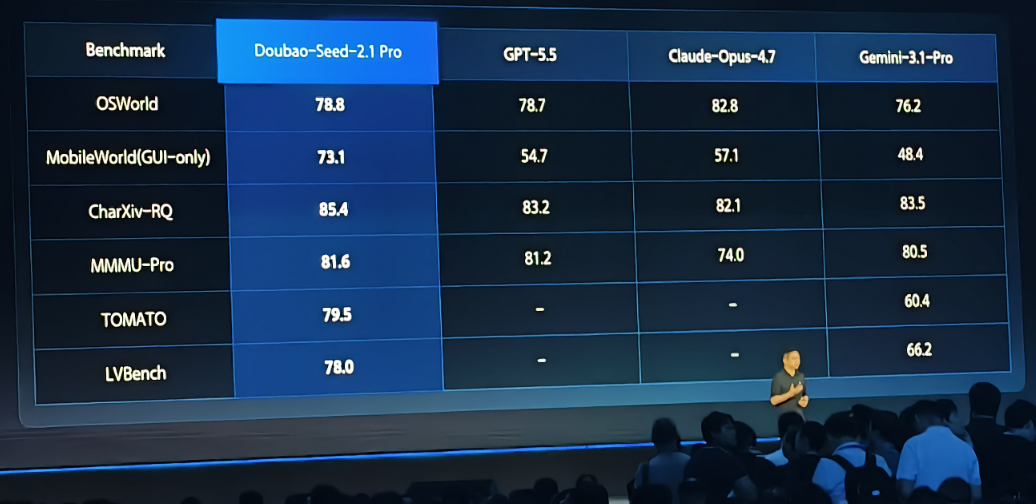
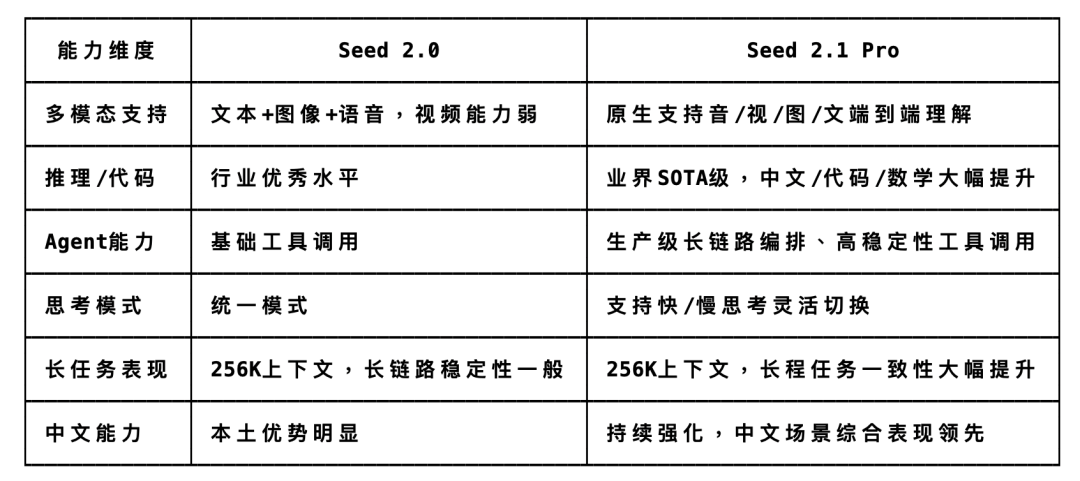
2.1pro的Agent和GUI操作能力很突出,OSWorld 78.8基本贴着 GPT-5.5 的 78.7;Coding编程能力也进入第一梯队了,Terminal Bench 2.1 是 71.0,接近 GPT-5.5和Claude;多模态和视觉理解提升比较大,CharXiv-RQ 85.4、MMMU-Pro 81.6、TOMATO 79.5、LVBench 78.0意味着文档,图表,截图,视频理解都能上。这个就是2.1pro没有skill的情况下搓出来的👇
这次 Seed 2.1 Pro相比 Seed 2.0,最核心的升级,其实就卡在这里。
2.0已经是一个很不错的强文本 + 基础多模态模型,文本,图像语音理解都能做,中文场景纯舒适区。2.1 Pro这次明显往更完整的全模态能力,推理代码能力,生产级的Agent能力上补了一大截。
它支持原生的音视频,图片,文本混合理解,也开始追上第一梯队了,长链路的工具调用,复杂任务规划,支持快思考和慢思考切换,以及256K上下文(什么时候能蹲到豆包的1M上下文啊啊啊)
用人话说,2.1 Pro开始更像一个可以被放进Agent里干活的执行模型了。
昨天晚上我就拿它跑了一大轮。
本来只是想找几张图,测测日常任务啥的,结果测着测着,给我整成了一轮小横测。。。
那来都来了,那就来一个原汁原味的模型大横测吧。从多模态图像理解,到DeepResearch报告,再到从0开始写PPT,后面又做了前端UI优化,再再再到后面搓了个世界杯网站,以及点球大战小游戏也都给我跑出来了。。
每天用Agent干的活,差不多就是依赖模型的这些能力。
需要强调的是下面跑的所有case都没有用到Skill的,没用ui pro skill没有头脑风暴skill没有用辅助模型,真实环境下跑出来的,差别还是很多大,GPT5.5没有skill的情况下做出来的前端文案全是它的思考过程,非常闹心。
我们工作流所在意的,也就这些。
先从代码能力说起。
1. 代码能力
我这次把任务按难度排了一下。
先让它修UI和Debug,再到一个网站,最后以一个小游戏结尾。
像真实开发,让他从基础开始实测。
我这次翻了一个之前的旧项目出来。
这种项目最烦的地方就是,它也不是完全不能用。页面也都能打开,但UI就是有点别扭。
有些地方挤在一起,有些地方间距不舒服,有些组件在移动端一缩就开始乱。
每天真的做产品,最消耗人的往往就是这种小东西。之前到这一步就要烧token让Claude头脑风暴自己优化自己了。
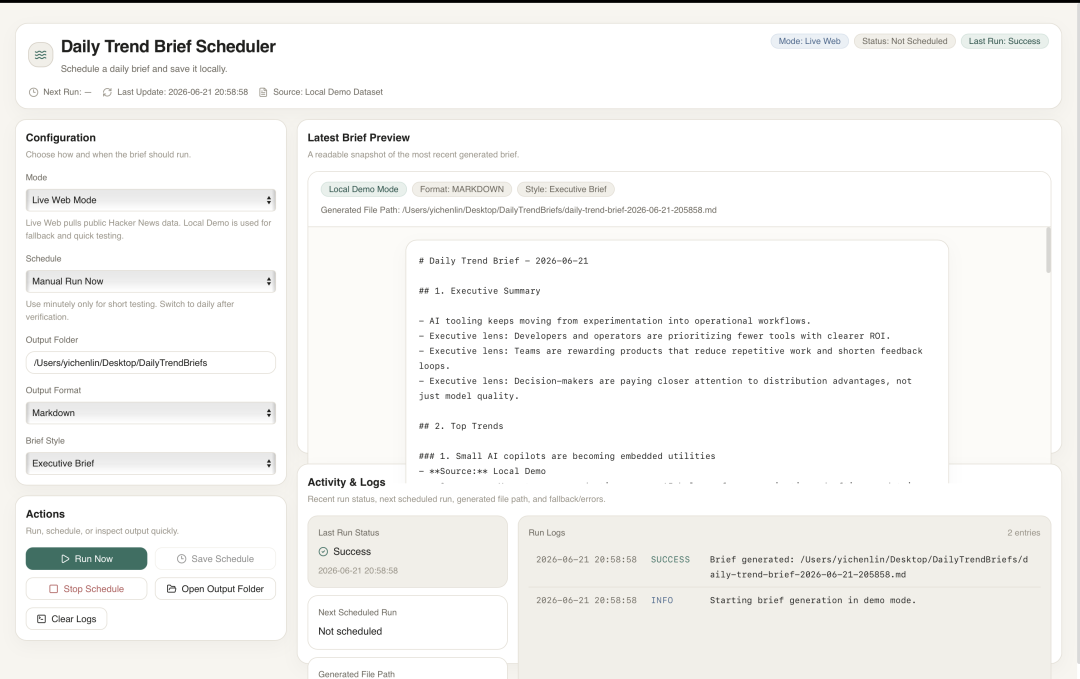
这次我把这个旧项目直接丢给豆包后,给了任务,看代码改Bug以及UI。
这类任务其实很考验模型。
从零生成的时候,可以自由发挥。
但改旧项目不一样,得先全程理解后在记问题。
如果上来就乱改,只会越修越怪。
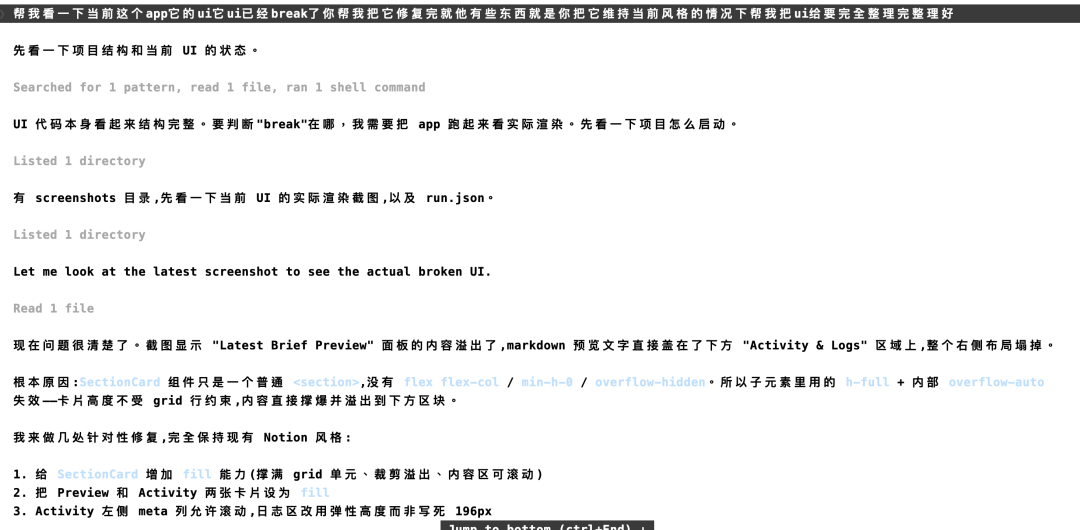
沿着项目结构去看组件,再去看样式和页面布局,最后才开始动代码。
在旧项目里找到真实的位置,再一点点把 UI 往正确方向拉。改完之后,效果就顺了很多。
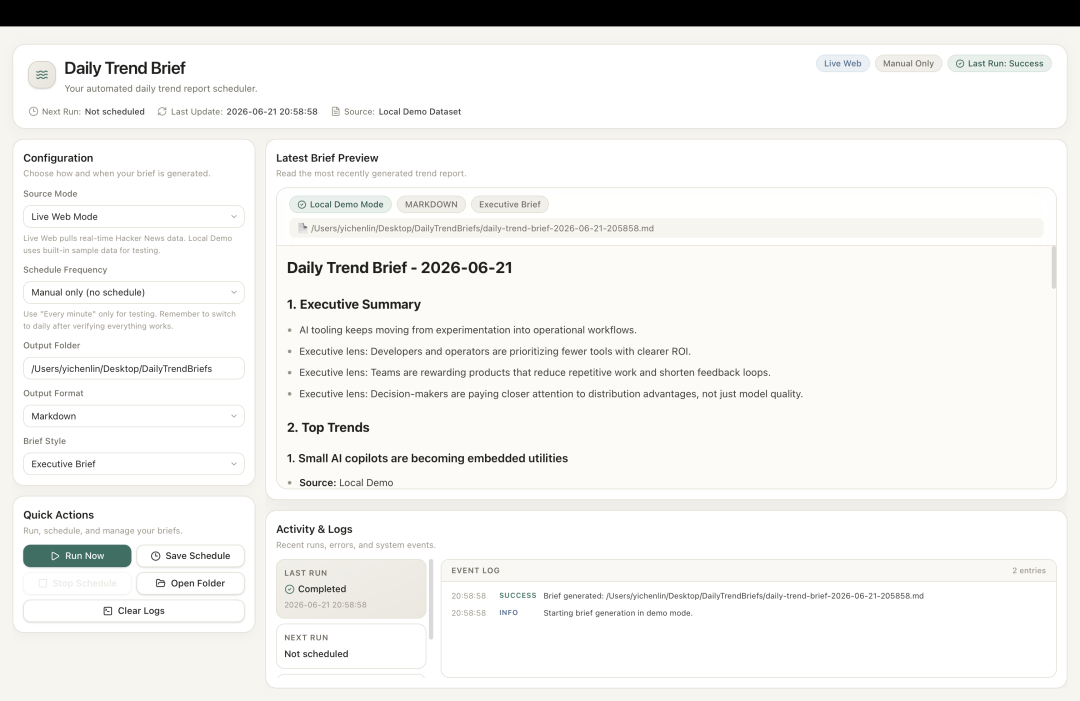
布局正常了,组件关系更清楚了。
页面也没有因为改UI把其他逻辑带崩。
说明还是能完成一个日常的开发闭环的。
Gogogo,我们下一关,
这个任务就比UI debug稍微大一点。
我让2.1pro做一个世界杯主题的网站,要有首页,赛程,球队,对阵图,还要能筛选比赛。
这种东西最容易翻车的地方,是模型只做出一个看起来很完整的静态页面。
点进去什么都没有,筛选也是假筛选。
数据也只是写死的几行字。但豆包这次做出来的东西,是一个能打开,能浏览,能继续改的版本。
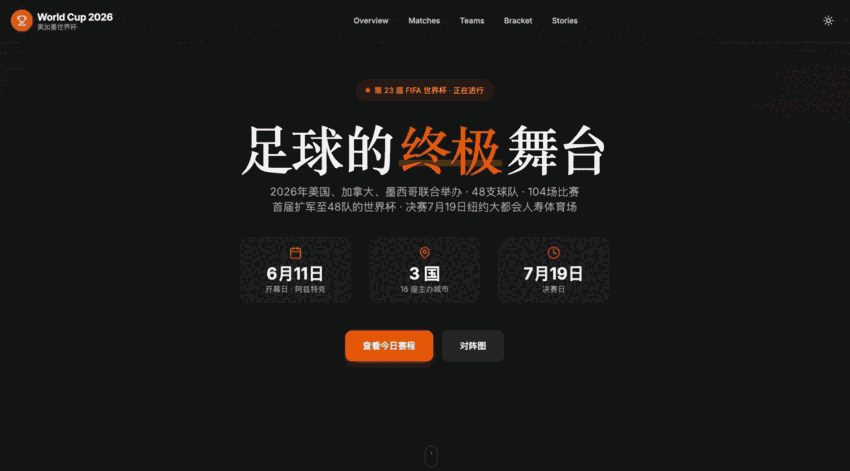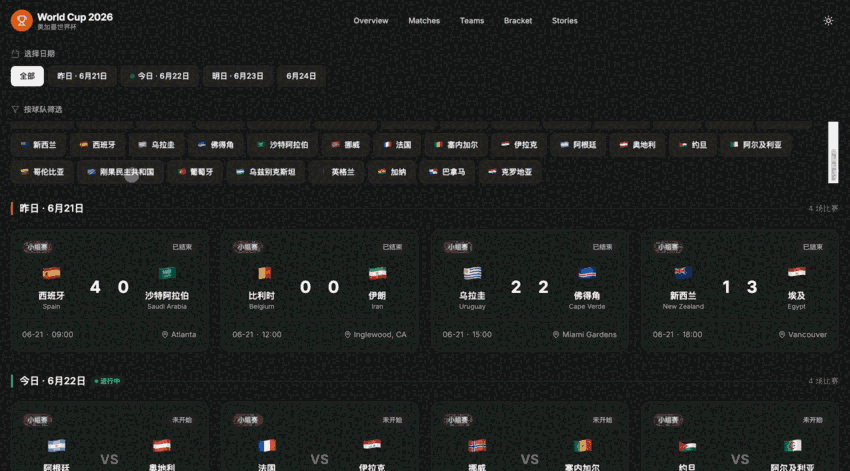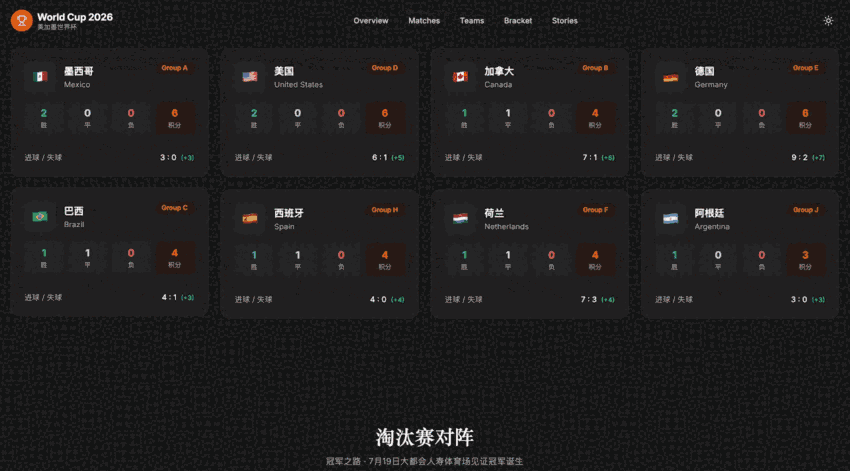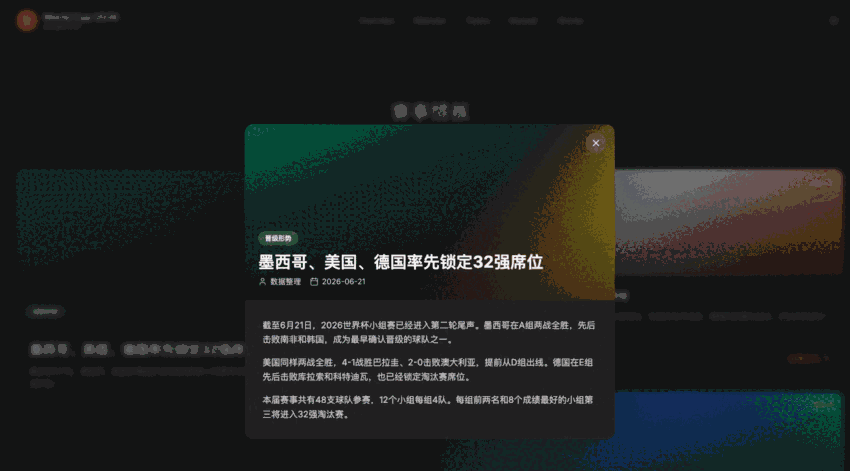
它把页面,赛程筛选,数据fallback,暗色模式这些基本东西都搭出来了。
也就是说,这个项目不是单纯的视觉Demo。
是有一点真实项目的骨架。
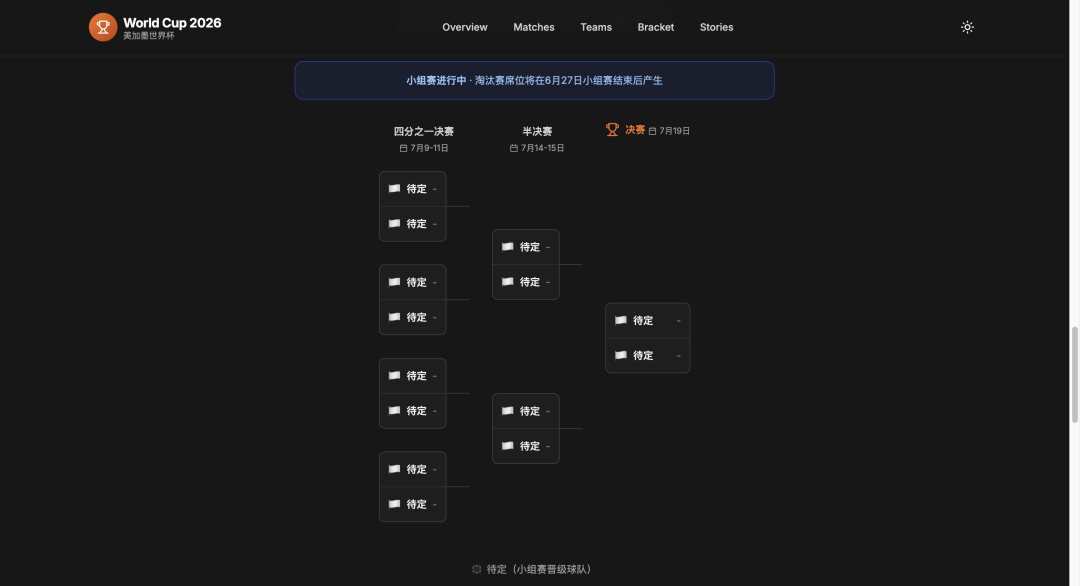
当然,审美还是老问题。
页面能用,但不惊艳。
渐变,卡片,圆角这些 AI 味还是能看出来。
如果这是一个正式官网,我肯定还要继续调视觉。
但如果目标是先把一个带业务逻辑的网站跑起来,我觉得它完成得不错。
那现在还很流行在网页里面放AI视频当背景,放点3D小游戏当交互,
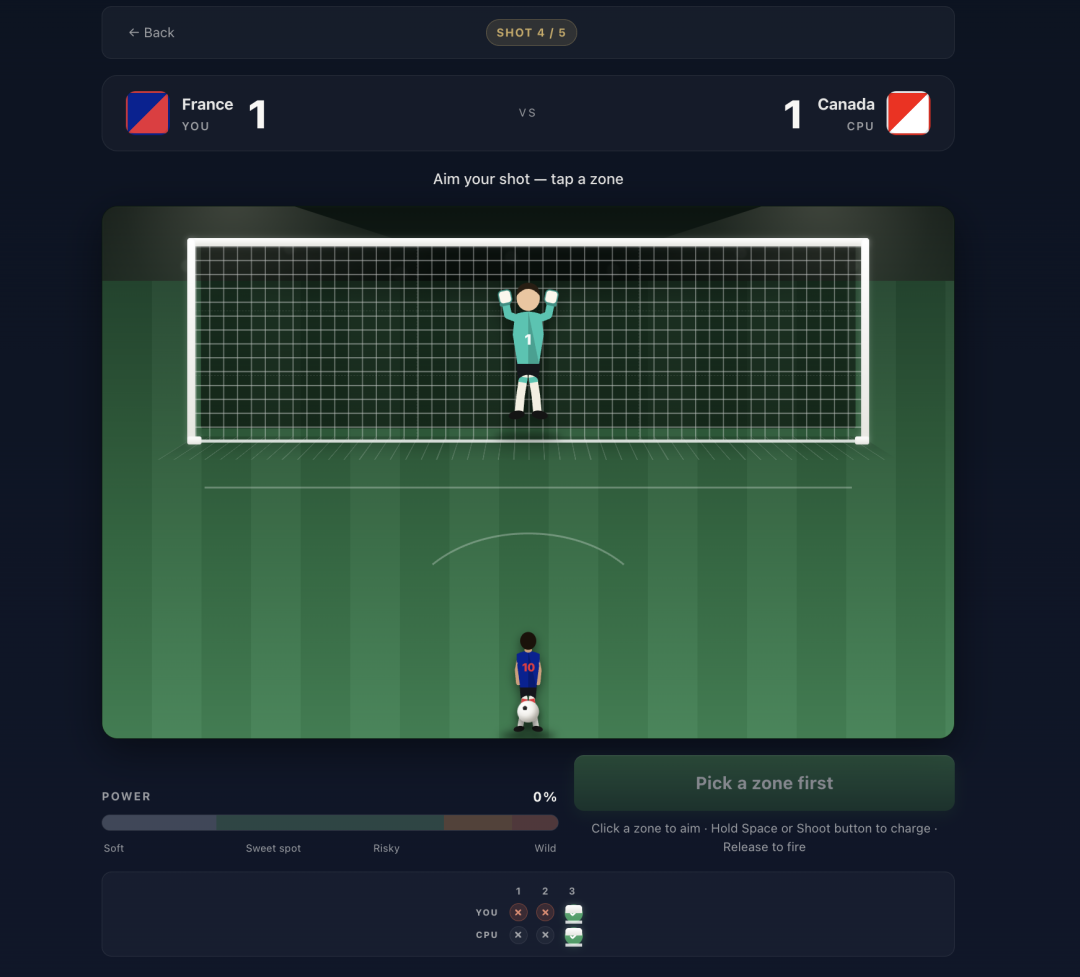
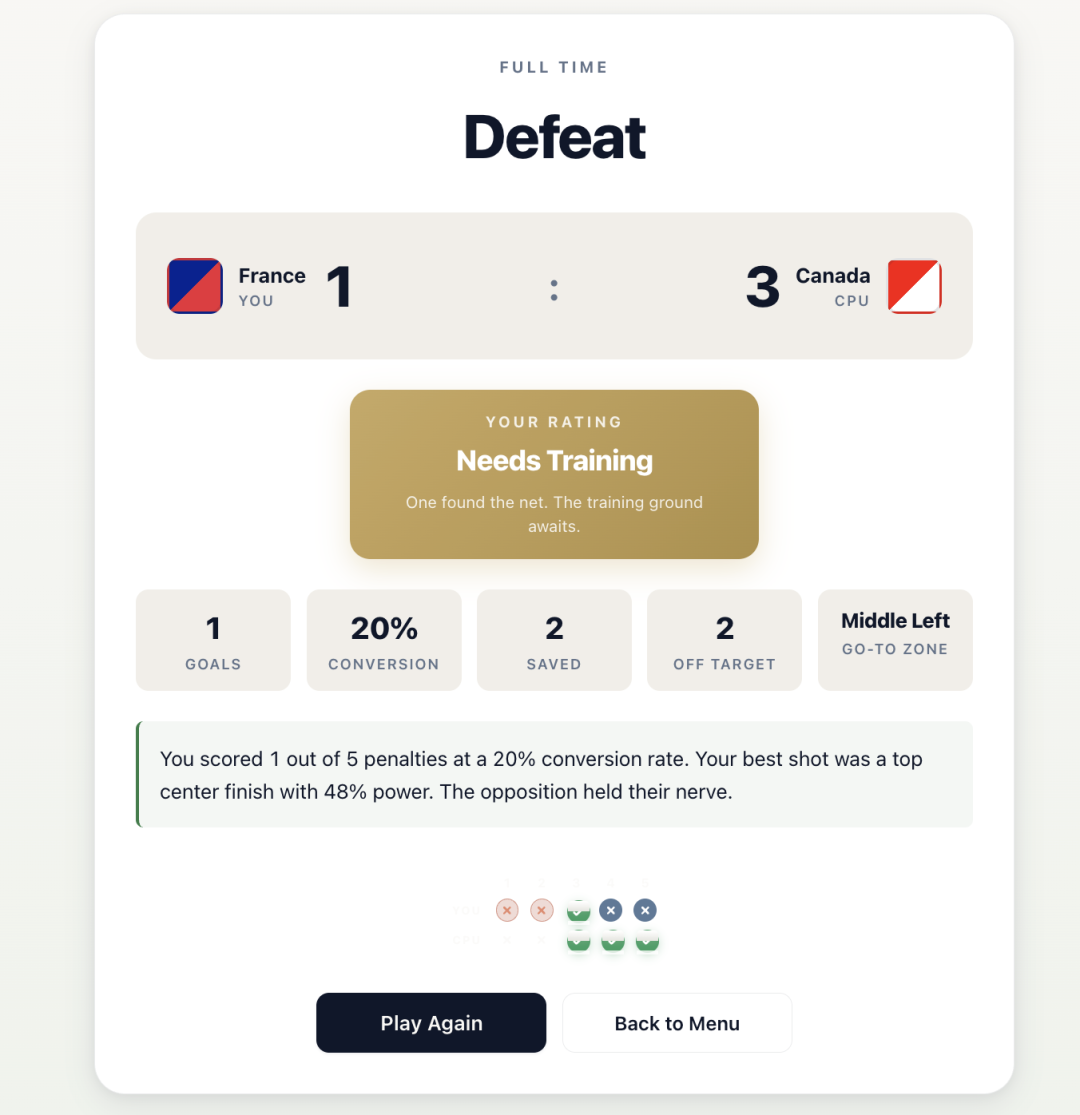
那我肯定不能不测这个,顺着世界杯主题做了一个点球大战,要求是必须有状态,有规则,有输入,有反馈,还要有输赢结算。
游戏交互还是挺想一回事的,玩家选队,选择射门方向,按住 Space 蓄力,松开射门。然后系统判断进球,扑出或者打偏。CPU 再踢一脚。五轮以后如果打平,还会进 sudden death。
从选队伍的开头到比赛结束的结尾,
整个流程在两轮后就被跑通了。

代码测完之后就要看看日常任务用最多的视觉理解,信息收集和PPT生成了(这应该也算是信息输入输出了)
2. 多模态理解

我先给了一张绘本风格的森林插画,
图里信息其实挺多的,有天空,草坡,前景小溪,还有一堆小动物围着听歌等等等等
如果是粗略的模型描述,可能一句话完了。
一群森林小动物在开音乐会。
但2.1pro没有停在这一层。

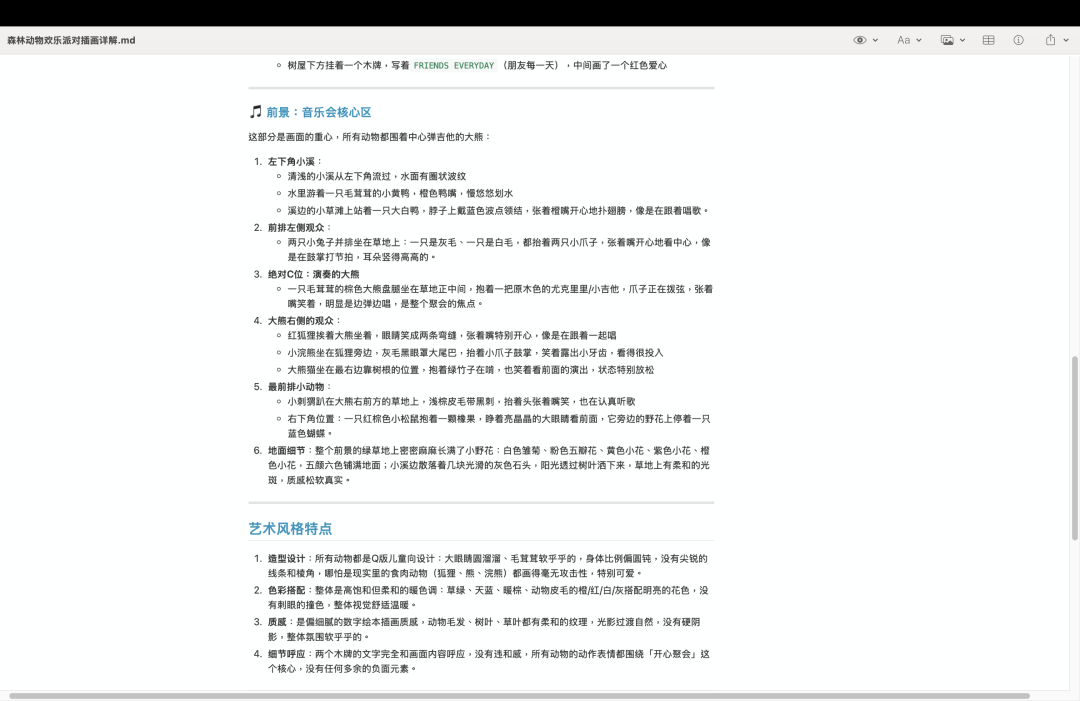
从远景到前景,从周遭到细节都完整的读取说明了。关键是,它还把这张图背后的主题风格提了出来,
还把一张图里的空间关系,关系文字,元素和情绪主题都拆清楚了。可以期待一下我们后面用来做视频剪辑和seedance 2.5 pro生成视频的提示语生成看看。
很多情况下,我们要的不是一句简单的图片描述,而是要把图片转成后续还能继续使用的文字资产。
所以多模态图片理解的价值,就是把信息结构化,语言化,以及可复用化。



除了对应这种AI视频画面的复杂关系,直接把一些论文相关或者是课程报告相关的数据图表,都丢给豆包 2.1 Pro,它也都能识别出来。
所以我就在想,明年的高考数学,豆包是不是要拿满分了。
3.报告分析DeepResearch
接着就是报告测试,我让它分析 MaaS,也就是模型即服务,以及 Agent 为什么会增长。
让他看大模型未来怎么从聊天工具变成能自己查资料,拆任务,跑流程,交付报告的工作助手。


这次我还要求它写清楚Source和Reference,也就是每个关键判断从哪里来。
同时观察它能不能自己启动Workflow,用Deep Search找资料,再整理成一份结构完整的分析报告。
因为这类报告型任务,如果没有逐条查来源,模型很容易写出一份看起来很真的东西。
但真要发公开文章,每个数据都要自己查证。
所以我这里看的不是2.1 pro能不能直接产出一份可发布报告,是它的结构能力,能不能把一个开放性问题拆成研究背景,市场增长,商业模式,竞争格局等一系列汇报。


半个小时后,报告新鲜出炉
有结构清晰足够的数据做为支撑,并且一开始就把结论给完整罗列。
不得不说这个成果报告我还是很满意的。
4.汇报PPT实测
顺着这个报告,又想到了工作里的PPT汇报也是避免不了的。
给了个题目,让豆包自己解释最新模型的优点,
自证自己不只是一个更聪明的聊天AI,是在能被塞进Agent框架里kuku干活的模型。

说实话,里面有些话还是有点发布会味儿。
比如生产级Agent临界点、数字员工底座这种表达,全都提了一次。


虽然画面UI较为固定,
但它把内容整理成演示稿的能力是成立的。
还是那句话,在不依赖Skill的时候能做出这样的水平,其实已经能够说明2.1 Pro是真的在往Agent模型的路上狂奔了。
所以这几轮测完,我对豆包2.1的评价其实已经有答案了。
它不是Opus,Sonnet,GPT的无脑替代。
复杂架构,强审美设计,关键事实判断,
还是要更强模型或者人来兜底。
但它已经很适合做执行层的模型。
看图拆解,写prompt,整理报告结构以及做PPT初稿。修旧项目UI,网站骨架和做一个能玩的小游戏原型。
这些活交给它,我是不担心完不成的。
而且这套用法的重点不只是便宜,
还有是分工。
不用非要证明它超过谁。
你只要知道哪些任务可以交给它,
哪些地方需要人审,
哪些关键节点要换更强模型。
它开始有了一个很实际很具体的位置。
一个能进我Agent工作流的执行型队友。
@ 作者 / 卡尔 & yc星辰
最后,感谢你看到这里👏如果喜欢这篇文章,不妨顺手给我们点赞|在看|转发|评论 📣
如果想要第一时间收到推送,不妨给我个星标🌟
如果你有更有趣的玩法,欢迎在评论区聊聊🤝
更多的内容正在不断填坑中……
