
日本 AI公司Sakana AI,把市面上最强的几大公开 AI 模型(Opus 4.8、Gemini 3.1 Pro、GPT 5.5)丢进一个池子,再训练一个很小的 AI 模型“指挥”去调度它们自动分工、自动协作。
结果这个组合体,在一连串硬核基准上,反超了池子里它所依赖的每一个单体模型,甚至性能和目前最强的已经被美国禁止的 Fable 5 和 Mythos Preview 不相上下...
这套系统的一个更精妙之处是,你这边看到的,始终只是一个模型、调用的是一个 API。
和你使用单个模型的体验一模一样,价格也只收你一份钱...
你现在用 AI,是"一个模型搞定一切"
不管是写代码、查资料还是做分析,你现在用的大部分 AI,通常是"一个模型搞定一切",它就像一个全能专家,什么都问他,看似能解决一切问题。
但其实这套用法有个绕不开的问题:没有哪个模型真的什么都最强。写代码这家顺手,推理那家更准,长文档又得换一个。你想每件事都用上最好的,就得自己判断哪个模型适合哪段活,还要同时接好几家的 API,管好几把 key,对好几份账单,连什么时候切到哪个模型,逻辑都得自己写。
还有一层风险常被忽略:把业务押在单一厂商上,断供、涨价、出口管制,没一样在你的控制范围内。
01各家都有短板编码强的可能推理弱,没有全能选手。
02接口管理很碎多接几家就是多管几把 key、几份账单。
03绑死一家有风险断供、涨价、管制,都不由你说了算。
背后是一个团队,对外只有一个联系人
Fugu 的思路反过来:它背后其实是一个团队,有人擅长写代码,有人擅长推理,有人擅长查资料。但你对外只需要找一个联系人,把任务丢给他,剩下的他自己安排,要不要分给团队、分给谁、最后怎么把结果汇总,全不用你操心。你完全不需要知道背后发生了什么。
具体到怎么用,你调用 Fugu,不像现在的那种Agent路由,跟调用 ChatGPT 的 API 一模一样,一个请求进去,一个回答出来。区别全在后台:Fugu 可能已经悄悄问了三四个不同的顶级专家模型(如GPT 5.5、Opus 4.8、Gemini 3.5、GLM5.2等等),把它们的答案合并成一个更好的结果,再交给你。
那么它是如何工作的?
先掂量,再分工:
它自己直接回答,不绕弯、不浪费资源。
比如 "帮我做一个完整的安全漏洞评估",它就自动拆解,分头执行,再把结果整合起来。
官方给它的定义就一句话,"一套多智能体系统,打包成一个模型"。多智能体(multi-agent)说的是里面那个团队,一个模型说的是你看到的那个联系人。
Fugu 自己决定叫谁上、谁先谁后,再把几个答案合并成一个更好的结果。这一整套,你都看不到,也不用管。
最特别的地方:分工是"学"出来的
你可能会想,让几个模型协作,不就是写个流程,先让 A 做、再让 B 检查吗?
Fugu 的关键差别就在这。它的分工不是工程师事先写死的固定流程,而是系统自己学出来的。针对每一个具体任务,它会自己琢磨该叫哪几个模型、谁先谁后、它们之间怎么沟通。很多时候,它找到的协作方式,是人想不到、但效率特别高的。
这套能力来自 Sakana AI 的两篇 ICLR 2026 论文。它们各自解决的问题,简单说是这样:
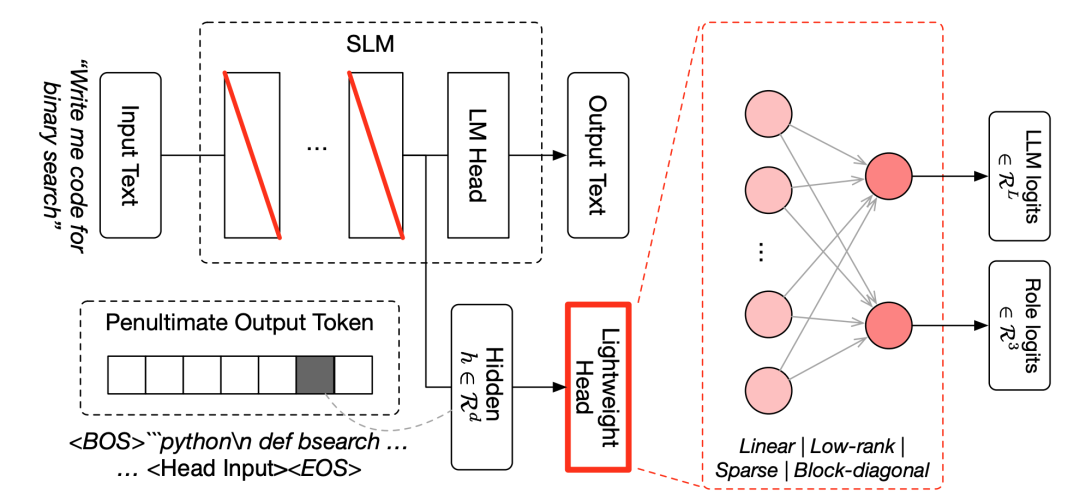
进化出来的协调器An Evolved LLM Coordinator
一个很轻量的"协调器"统筹多个模型,跨多轮对话给每个模型派角色,按编码、数学、推理、知识等不同任务,把活灵活分下去。
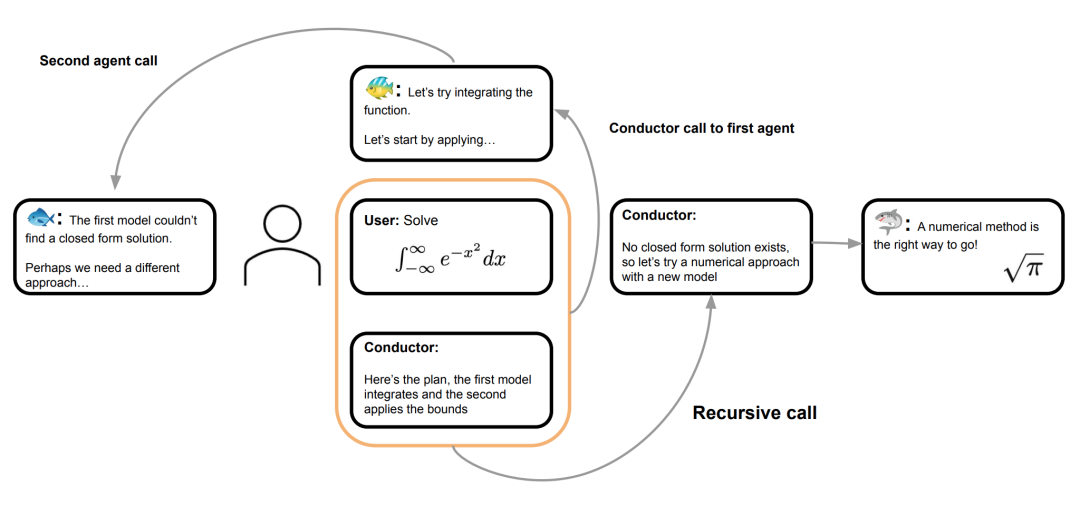
用大白话指挥一群模型Orchestrate Agents in Natural Language
用强化学习训练,让系统自己摸索出协作策略,包括模型之间怎么对话、给谁什么提示。结果是一群普通模型协作起来,能在硬核推理上跑赢单个高手。
arXiv · TRINITY 论文 ↗:
https://arxiv.org/abs/2512.04695
arXiv · Conductor 论文 ↗
https://arxiv.org/abs/2512.04388
完整技术报告 ↗
https://github.com/SakanaAI/fugu/blob/main/Fugu_technical_report.pdf
Fugu 和 Fugu Ultra,按需选
两个型号走的是同一个 OpenAI 兼容 API,换型号不用改对接。
性能和低延迟兼顾,适合每天的活。接进 Codex 写代码、做代码审查,或者驱动要快速响应的聊天机器人。
调动更深的专家模型池子,专攻难、重要、容不得出错的问题。早期用户拿它做 Kaggle 比赛、复现论文、网络安全分析、文献和专利调研。
落到实处,它对你有用的三点
前面那些原理讲清楚了,对你实际有用的好处,可以归成三件事。
一个 API,自动用上所有模型
一个接口背后是一池子专门模型,每个任务该用哪个、什么时候切,Fugu 替你决定。你不用再同时维护好几家的接入,也不用自己写切换逻辑,省事还更划算。
复杂任务上更稳更准
专为写代码、推理这类对质量要求高的活设计。多个专家模型协同、互相校对,碰上多步骤的复杂任务,结果比单个模型更可靠。
能自己挑用哪些模型
你能控制哪些模型进池子。某个厂商或某个模型出于数据、隐私、合规考虑不想用,可以直接剔掉。
11 个硬核基准,拿下 10 个第一
官方把两个 Fugu 模型放进一堆工程、科学、推理基准,和公开可用的前沿模型比。结果是:11 个里赢了 10 个,只有长上下文检索(MRCRv2)输给 GPT 5.5。官方还称,它和 Fable 5、Mythos Preview 打平,而且没有出口管制的风险。
加粗高亮=该项最高分,下划线=第二名。* SWE Bench Pro 用 mini-swe-agent 作为脚手架。† 对比模型采用其官方公布分数。Fable 5 与 Mythos Preview 未公开,不在 Fugu 的模型池内,故未列入对比表。
不止跑分,六个真任务里的表现
下面每个案例,都把 Fugu 和三个前沿模型放进同一套流程对比(对手匿名为 Model A/B/C)。
让 AI 自己调训练配方
AI 反复改训练代码、跑实验、只留更好的版本。单张 H100、约 14 小时、123 次实验。
✓BPB 压到 0.9774,三个前沿模型都没它低
还原日本仮名消息的阅读顺序
1610 年的散着写古文书,连专家都难判读序。各模型写代码推断字的先后。
✓NED 0.80,对手最高仅 0.24
纯 Python 从零写求解器
不许用现成库,跑 300 个打乱的魔方。比谁解得开、谁步数少。
✓平均 19.72 步全解,两个对手代码直接崩
做像相机光圈的联动机构
多片叶片绕轴转动、协同开合中央的孔。比谁的结构能真正动起来。
✓叶片干净开合,对手漏光、关不严
连下四局不看棋盘
全程靠记忆保持棋局,连续对弈四局。对手是三个前沿模型加一个引擎。
✓击败 2100 Elo 的 Stockfish,局局将死
逐周做买卖决策
单只匿名股票 50 周窗口,不能预知未来,只能看历史数据逐步决策。
✓平均收益 +19.43%,对手都不到 +15%
案例 06 仅用于比较逐次、无先读的决策方式,并非证明可泛化的交易表现。过往结果不代表未来,也不一定适用于其他资产、时段或真实市场。
早期用户的真实反馈
做代码审查,Fugu Ultra 明显比 GPT-5.5 强,回答很全,能找出别人漏掉的 bug。别的工具指出三个问题,它能洗出二十多个。现在我所有审查都过它一遍。
梳理 20 篇论文加几项专利的专利全景,平时要三到四天。用 Fugu 几个小时就出了完整分析,还找出了我自己绝对发现不了的论文间联系。
原始输出质量和顶级前沿模型持平。但 Fugu 在长会话里人格特别稳,别的模型会跑偏它不会。对 Agent 产品来说,这比跑分更重要。
一个简单指令,Fugu 自主跑了快四个小时,读论文、实现、训练、评估、分析差距全做了。一个 CUDA 任务,单次会话做到 100 倍以上加速。
给一条限定范围的指令,它端到端做完整个安全评估,信息收集、XSS/SQLi 检查、认证审查,最后一份带证据和复测步骤的报告。全程没越界,也没做破坏性操作。
订阅和按量,两种都行
每一档都同时包含 Fugu 和 Fugu Ultra。订阅适合个人和日常上手,按量适合高负荷生产。
Fugu · 不叠加收费
只用一个模型,就按那个模型的标准价。多个模型同时跑时,绝不把费用累加,只按其中最高档那个模型,收一个价。加再多 Agent,账单也不翻倍。
Fugu Ultra · 固定价
型号 fugu-ultra-20260615,每百万 token:
输入 Input$5
输出 Output$30
缓存输入 Cached$0.50
上下文超 272K 时$10 / $45 / $1.00
一些局限性:
省心是有代价的。这几点先看清楚,再决定要不要上。
!欧盟、欧洲经济区暂时用不了官方在做 GDPR 合规。日本以外其他地区一般可用,但可能受网络环境或当地法规影响。
?路由是黑盒,看不到调了谁它每次到底用了哪些模型、怎么协调,官方说这是核心技术,按设计不对外公开。
×Ultra 的池子不能剔除Fugu Ultra 靠完整模型池发挥性能,池子固定。有合规硬要求要剔模型的话,只能用 Fugu。
~Ultra 换质量牺牲速度Ultra 追求回答质量,响应时间更长。要快速响应的场景,更适合用 Fugu。
▢数据默认会用于改进使用数据默认会拿去优化模型,不过可以在控制台随时关掉这一项。
↻更新有延迟有新前沿模型公开后,官方预计要花约两周训练、评估,再把更新版的 Fugu 推出来。
它把"选模型",变成了模型自己的事
过去你要自己判断哪个模型适合哪个任务,还要自己接、自己切、自己付。Fugu 把这一层全收进一个 API,由一个学出来的协调器替你组队。你失去的是对底层模型的可见和掌控,换来的是更省心的接入,和复杂任务上更稳的结果。值不值,看你更在意哪一头。
产品页面: sakana.ai/fugu